Predicting Diabetes Using Logistic Regression and SciKit
The following analysis will use data from a hospital that tracks the prevalance of diabetes in patients with suspected contributing factors measured as well. My goal is to help the patients prevent diabetes. I am going to create a logistic regression model so I can predict when a patient is on track to enter the diabetes range.
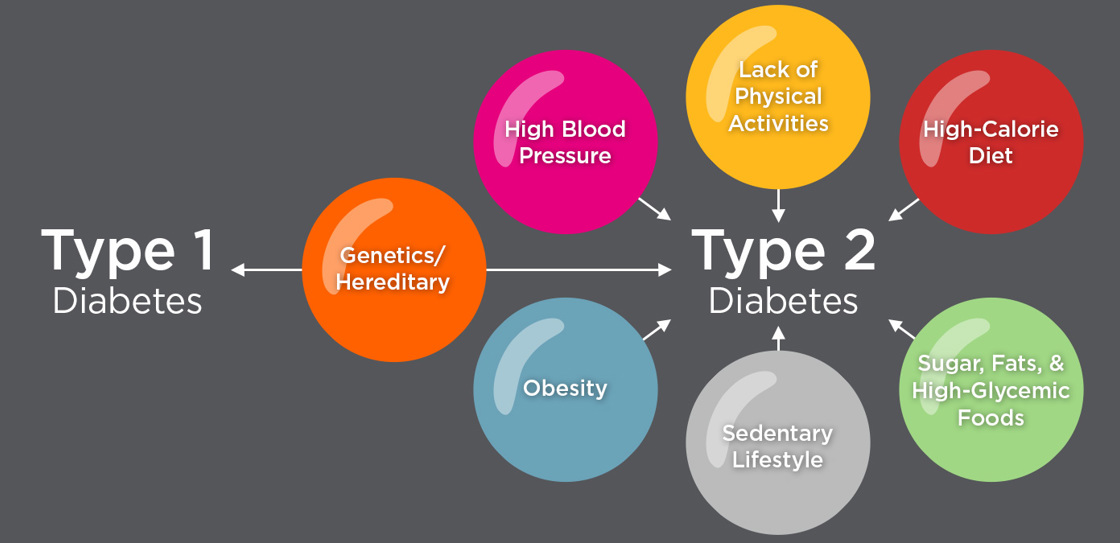
As the graphic shows, type 2 diabetes is a preventable disease since most of the contributing factors can be controlled. The predictor varaibles in our dataset are:
- Pregnancies
- Glucose
- BloodPressure
- SkinThickness
- Insulin
- BMI
- DiabetesPedigreeFunction - calculates diabetes likelihood depending on the subject's age and his/her diabetic family history
- Age
- Outcome - 1 if the patient has diabetes and 0 if not
